형태소 분석 간단히 알아보고 넘어가기
KoNLPy는 다음과 같은 다양한 형태소 분석, 태깅 라이브러리를 파이썬에서 쉽게 사용할 수 있도록 모아놓았다.
- Hannanum: 한나눔. KAIST Semantic Web Research Center 개발.
- Kkma: 꼬꼬마. 서울대학교 IDS(Intelligent Data Systems) 연구실 개발.
- Komoran: 코모란. Shineware에서 개발.
- Mecab: 메카브. 일본어용 형태소 분석기를 한국어를 사용할 수 있도록 수정.
- Open Korean Text: 오픈 소스 한국어 분석기. 과거 트위터 형태소 분석기.
영화 한 개에 대한 빈도 분석과 워드 클라우드
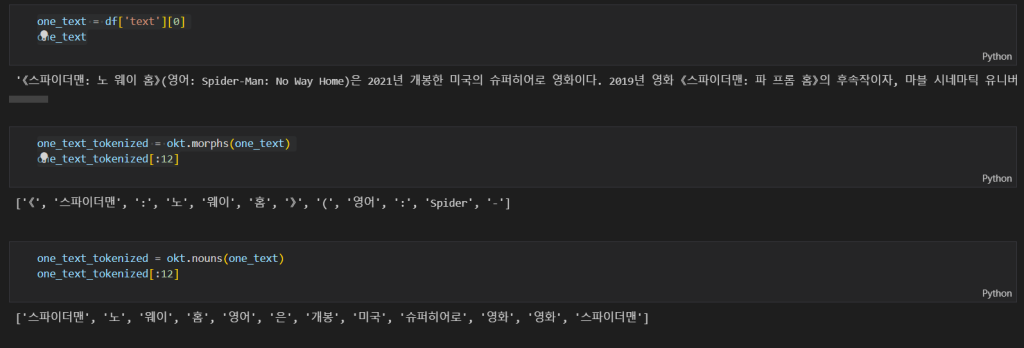
one_text에 okt 형태소 분석기를 이용해서 앞에서 12개[:12] 만 분석을 해보도록 합니다.
nouns: 명사 추출morphs: 형태소 추출pos: 품사 부착
이번 실습에서는 명사만을 이용해서 분석을 실시하도록 해보겠습니다.
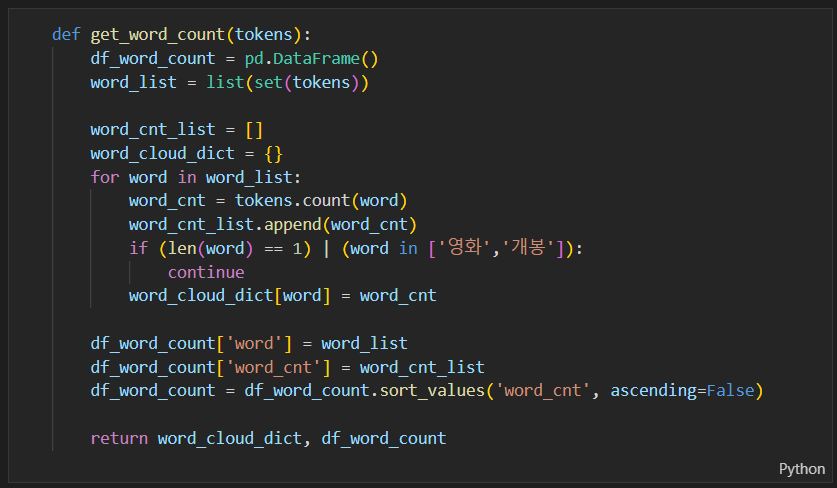
단어별 빈도수를 계산해 df_word_count 변수에 담아보도록 할께요.
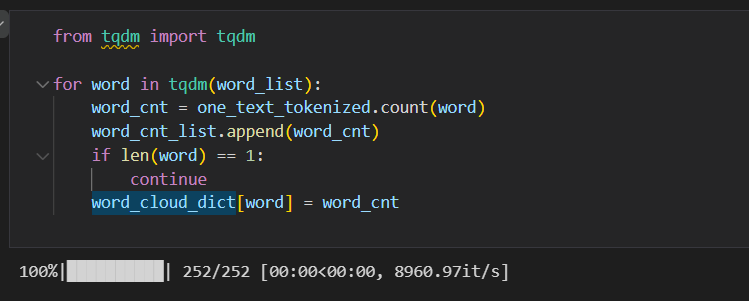
word_cloud_dict = {} 딕셔너리를 만들어 주세요. 여기서 key는 명사들이고 value는 count가 되겠죠? word_list = list(set(one_text_tokenized))는 set함수를 이용해 중복되지 않는 단어만을 넣고, word_cnt_list = []는 이 가각의 워드리스트에 있는 갯수를 넣는 리스트를 만들었어요.

tqdm을 사용하면 반목문을 사용할 때 얼마나 시간이 흘렀는지를 확인할 수 있습니다.
word_cnt = one_text_tokenized.count(word)는 word가 one_text_tokenized된 단어들이 있어요. 각 단어의 갯수를 센 다음에 word_cnt에 담아주라는 뜻입니다. 그리고 word_cnt_list.append(word_cnt) 명령어를 이용해 word_cnt_list에 하나씩 집어 넣어 주는 코드에요. 그리고 만약 단어의 빈도가 1개라면 제외하라는 코드도 넣어 줬습니다.
그리고 만든 df_word_count에 넣어주라는 코드입니다. df_word_count = df_word_count.sort_values(‘word_cnt’, ascending=False)는 word_cnt를 기준으로 내림차순으로 정렬하라는 코드 입니다.

워드클라우드 만들기
워드클라우드를 만들어 보도록 할께요. 아래 코드는 1000*600 크기의 워드클라우드를 처음에 설치했던 나눔고딕폰트로 만들라는 코드에요. word_cloud_dict는 키와 값으로 구성되어 있습니다. (단어와 빈도수)
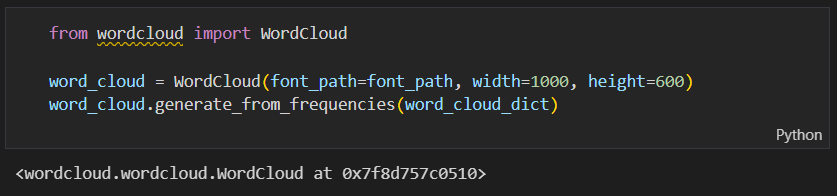
워드클라우드로 시각화를 위해 word_cloud.to_array() 명령어를 이용해서 word_cloud_array 변수에 넣어주겠습니다.

plt.imshow(word_cloud)array)명령어를 이용해서 워드클라우드를 시각화합니다. 텍스트에 대한 시각화를 확인할 수 있습니다.

여러개의 영화별 빈도 분석과 워드 클라우드 만들기
여러개의 영화별 빈도 분석을 한번에 처리하고 결과를 파일로 저장해 보도록 할께요. 우리는 146개의 영화 정보를 가지고 있어요. 그런데 설명이 짧거나 거의 없는 것들도 있어서 텍스트의 길이가 100개 이상이 되는 것만 분석해 보도록 하겠습니다. 총 87개가 나왔습니다. 그리고 인덱스를 세로 reset 해 주겠습니다.
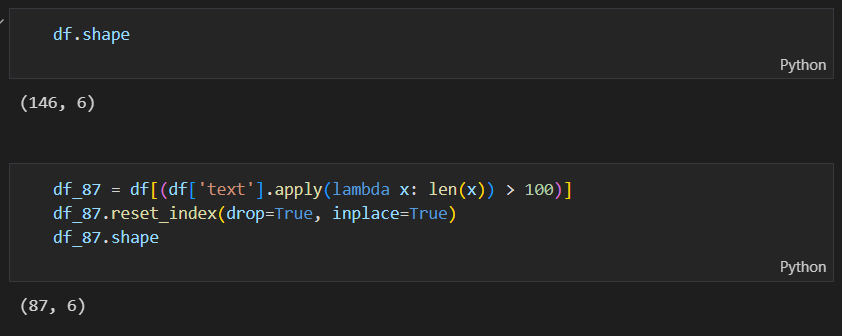
아래 함수를 간단히 설명해보면, (df[‘text’].apply(lambda x: len(x)) > 100) 값은 True 아니면 False의 값입니다. 그런데 여기에 기존에 df에 [ ] 안으로 넣어주면 True 값만 들어가게 됩니다. 그리고 이것을 len () 함수로 갯수를 구해보니 87개라는 결과가 나온거에요.

영화 87개에 대해서 반복적으로 형태소 분석을 실시할 것이기 때문에 for 반복문을 사용했어요. 여기서는 명사(nouns)에 대한 형태소 분석만 진행하구요. 형태소 분석된 tokens들을 새로 만든 tokens_list에다가 집어 넣도록 하겠습니다. 그래서 tokens_list에는 87개 영화에 대한 토큰화 된 리스트들이 담기게 됩니다.
tokens_list[0] 번째를 확인해 보면 스파이더맨 영화에 대한 형태소분석 결과가 조회 되겠죠?

get_word_count(tokens) 함수를 만들었는데요. 입력값은 tokens 입니다. 위에서 만든 tokens_list = []에 있는 하나하나의 토큰들을 넣으면 결과값으로 word_cloud_dict (단어별 빈도수가 있는 딕셔너리)를 얻을 수도 있고, df_word_count(단어와 빈도가 있는 데이터프레임) 도 얻을 수 있는 함수입니다.
불용어 처리를 할때 단어가 1개만 나오는것 외에도 영화나 개봉이라는 단어는 불용어 처리를 하였습니다.
87개 영화에 대한 빈도분석과 그 결과를 저장할 수 있는 함수를 만든 화면입니다.
ROOT_PATH에 지정된 폴더가 있는지 꼭 확인해야 그 경로에 저장이 됩니다.

경로 확인해 볼 것!!

연도별 월별 영화 빈도분석과 워드 클라우드
연도별 월별로 분석을 하면 영화 시장의 트렌드를 월별 년도별로 알아볼 수 있습니다. 꼭 영화에서만 해당되는 것이 아니라 정치, 여행, 맛집에서도 특정 시기에 따른 트렌드를 확인할 수 있는 장점이 있으니 여러 분야에 적용해 보면 좋겠죠?
먼저 구글드라이브에 접속해서 연도별/월별 폴더를 새로 만들기를 통해 만들어 주세요.
이번에는 87개가 아닌 전체 영화를 대상으로 분석을 해보도록 하겠습니다. 먼저 df.info()를 확인해 볼께요. 여기서 중요한 게 개봉일 입니다.

df[‘연도’] = df[‘개봉일’].apply(lambda x: x.year) 는 개봉일에서 apply 함수를 이용하면 각각의 x 값에서 year을 적용해 보겠다는 이야기 입니다. 개별적으로 df[‘개봉일’].apply(lambda x: x.year)만 출력해보시기 바랍니다. 그리고 추출된 값을 df[‘연도’] 열에 담게 됩니다.
이런식으로 똑같이 월에도 적용을 해서 df[‘월’] 에 담도록 해주세요.

tokens = [] 라는 리스트에 2021년도에 모든 영화의 형태소 분석 자료를 반복해서 넣는 코드에요.

4338개의 토큰이 담겼습니다.

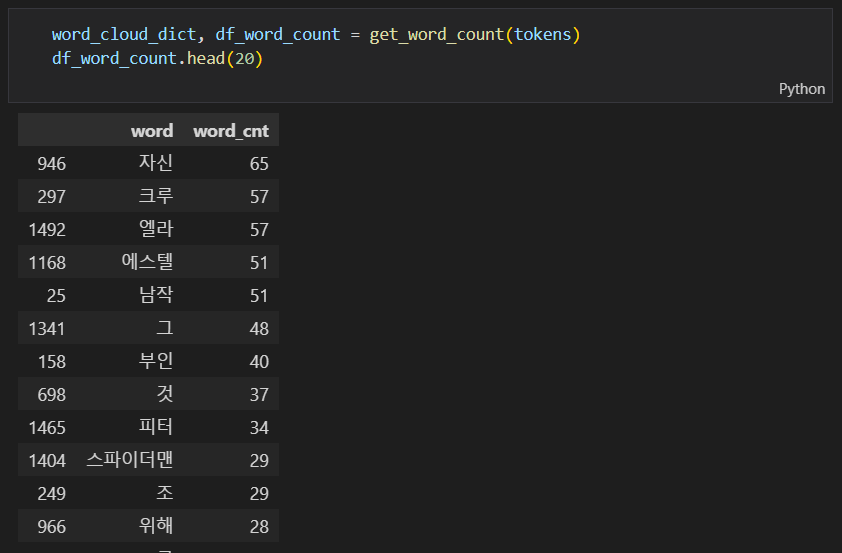
앞에서 만들었던 get_word_count(tokens) 함수를 이용해서 결과를 분석해 보도록 하겠습니다. 상위 20개의 결과를 확인해 보면 아래와 같아요.
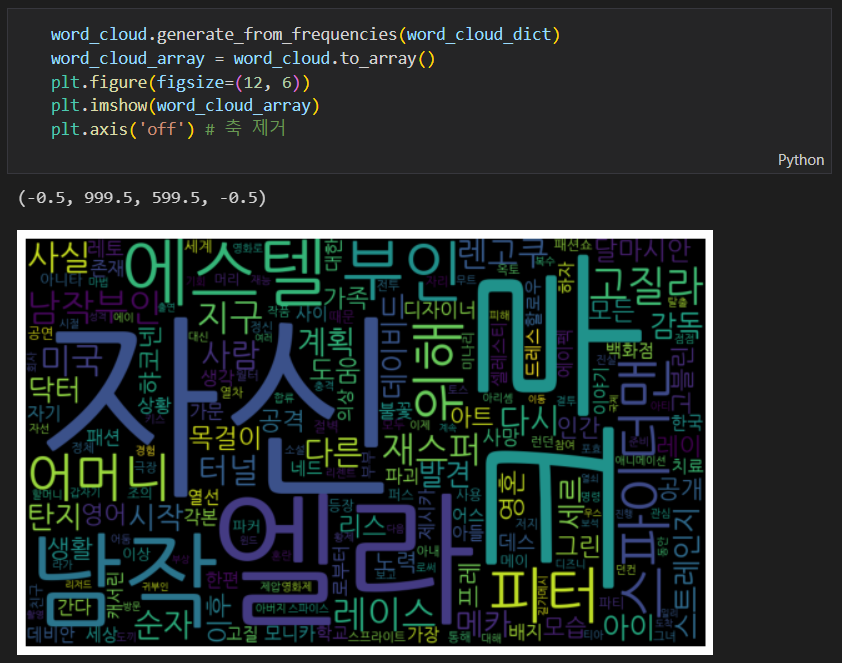
방금 만든 2021년 형태소 분석 결과를 워드클라우드로 불러와 시각화 해 보도록 할께요.
하나하나 분석하면 비효율적이죠? 반복문을 사용해 보겠습니다.
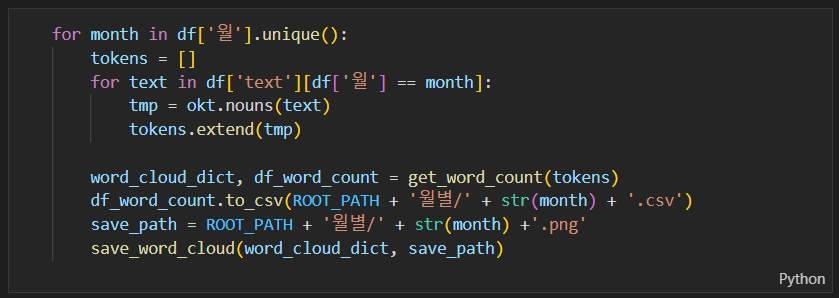
.unique라는 함수를 사용하면 df[‘연도’]에 들어있는 unique한 값들이 year에 담겨 반복이 됩니다. 아까 위에서 작성한 코드랑 동일합니다. 해당 연도에 해당하는 text에 대해서 형태소 분석을 실행하고 결과값을 tokens = [] 리스트에 담기게 됩니다.
get_word_count(tokens) 를 이용해서 word_cloud_dict, df_word_count 를 추출합니다. 그리고 결과를 csv 파일로 저장하게 됩니다.

월도 똑같이 작업해 주세요.
다음 시간에는 챕터 3으로 넘어가서 딥러닝을 활용한 단어의 벡터 표현 (Word2Vec)에 대해 배워보겠습니다.
끝.